A playground to practice differential privacy - Antigranular
#differential-privacy #pet- Background
- What is Antigranular
- My quick walkthrough - as a non-data engineer
- Why I think it is useful
- How I think as a security engineer

Background
I knew Jack from Oblivious (His company was called Oblivious AI then) early this year when I was researching companies that use AWS Nitro Enclaves.
At that time, their tool was just helping users deploy simple applications in the enclaves, and I didn’t understand how it was related to data science or even AI.
Last month in AWS re:Invent, I met Jack in person for the first time. After a great chat with him, I finally understood what his company was trying to achieve.
And today’s post is to share my first-glance view on the Oblivious platform - Antigranular
What is Antigranular
Antigranular is a Kaggle-like platform where we can play with various datasets, joining competitions on machine learning and data science using those datasets.
The difference from Kaggle is that Antigranular’s dataset is not freely available. Instead, there are restrictions on how users can access their data in order to guarantee data privacy.
There is another blog post by Bex T. talking about what is Antigranular, what technique it is applying, and how to get started. You can read it if you are interested in the details.
My quick walkthrough - as a non-data engineer
I’m not a data engineer, and I don’t even know the difference between pandas and numpy.
But I still tried to create my Jupyter notebook to play with one sandbox competition on Antigranular.
If you are also not a data engineer and have no idea how DataFrame works, my walkthrough may help you understand Antigranular and differential privacy.
Create a Jupyter Notebook
To play with the dataset, we first must create a Jupyter notebook, a powerful and popular tool among data engineers. I created mine on Google Colab.
Jupyter notebook can run different programming languages. Since Antigranular provides a Python library, I will be using Python.
Running some basic data engineering tasks
Before playing with the dataset, I need to mention a major difference between Antigranular and other data platforms - The data is not loaded into our Jupyter notebook.
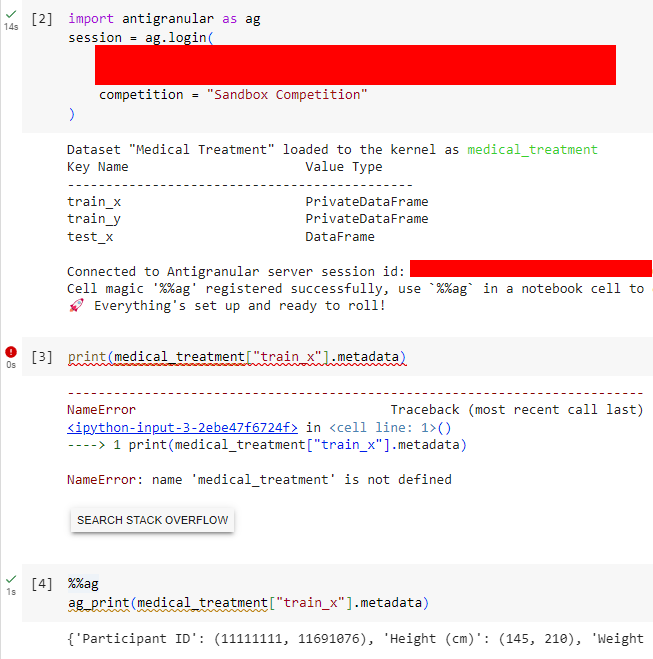
You can see from the screenshot that if I access the data and try to get its metadata, it will raise an error.
Instead, the data is being loaded in a trusted execution environment (TEE) hosted by Antigranular.
To access the TEE, we must add a magic function %%ag into the code block. The magic is that we can only use limited libraries and functions in those code blocks.
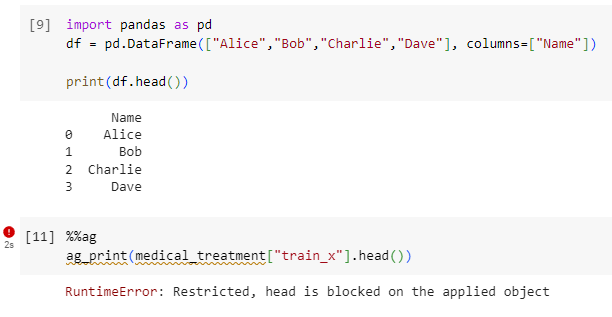
Data engineers usually use the head() function to preview the data. But with op_pandas, this action is blocked.
With these restrictions, the Antigranular platform can assure data providers that the individual privacy inside the dataset is protected.
Do some machine learning tasks
Now, we know that Antigranular runtime is an environment with limited visibility to the dataset. But what is our goal?
Inside the dataset, there are training data and testing data. We need to use our limited access to the training data to train an ML model. Then, it is used to predict the outcome from the testing data.
The catch is that our privacy budget will be used whenever we access the training data.
I’m not a data scientist, so I won’t explain privacy budget and differential privacy in detail.
But the idea is that:
If we run enough amount of targeted queries on a dataset, we can interpolate some detail from an individual record.
And differential privacy is all about limiting such a scenario. The less privacy budget we use, the less likely we can interpolate individual records.
Of course, if we want to train a good ML model, we should train it with accurate data. But the catch here is that we also want to protect individual privacy.
So, the competition on Antigranular is to train an ML model using as little of a privacy budget as possible. And use it to predict the test data as accurately as possible and submit that prediction result.

I know little about supervised ML, so I used a simple Gaussian Naive Bayes model trained by the training data with 0.1 privacy budget (or epsilon).
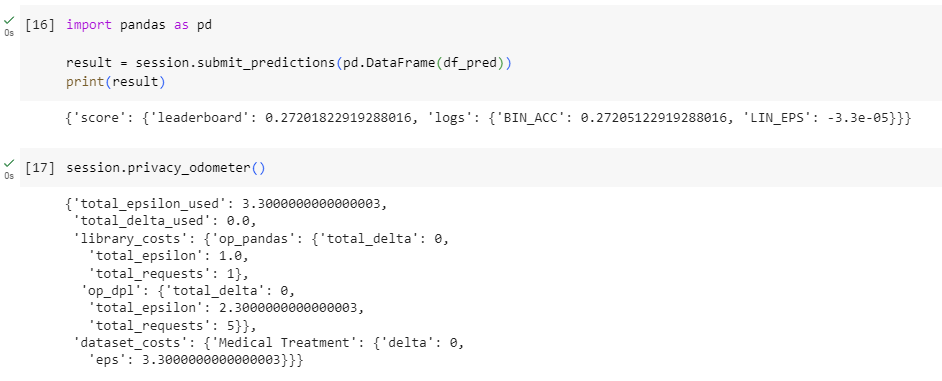
Then, I used the model to predict the outcome from the test data and submitted it.
As expected, I got around 0.27 points, far lower than other submissions, at around 0.7.
Another thing we can see here is the privacy budget I’ve used so far (i.e. total_epsilon_used) on the data.
Why I think it is useful
Many Privacy Enhancing Technologies (PET) are emerging, like Trusted Execution Environment, Homomorphic Encryption, Synthetic data, etc. Most of them only require the skills and knowledge of the developers.
However, for differential privacy, the users must also have the skills. We can see from the walkthrough that even how we query the data or how many queries we run will affect the privacy budget we will be using.
Not just for engineers, data analysts also need to learn how to interact with Differentially Private datasets. And I think Antigranular is a great place to play and learn.
How I think as a security engineer
After talking about data engineering, let me come back to my security engineer role. How do I think about it?
Verifiable TEE
The core of Trusted Execution Environment (TEE) is to ensure data is being processed in a trusted hardware that is running a trusted software.
The core part of oblv_client library, which is used by antigranular library to connect with the TEE runtime on Antigranular, is compiled so I can’t see if they are using the process to verify if the code is running on a genuine AWS Nitro Enclaves. But I tend to believe it is.
The other question is the trusted software. From the documentation and the GitHub page of Antigranular, I cannot find any code of their TEE. The fingerprint of the TEE, which the client will verify against during the Jupyter notebook initialization, is from an Antigranular API. So, we can only trust that the software inside the TEE is safe and honest.
Even though we trust Antigranular or maybe some parties can access the source code of the TEE, there is still another problem: Reproducible build
To verify whether a TEE is running the exact same software, we must ensure the fingerprint is always the same.
But many factors can make the compiled software different, e.g. time of build, software dependencies, etc., especially when the Antigranular runtime relies on many libraries written in Python, which is always inconsistent during build time.
Threat modelling
A common way to do threat modelling in cybersecurity is to ask: Is it a risk? How critical is it? How to mitigate it? How do we detect it?
But for differential privacy, it’s a little bit tricky.
Is the data critical? Yes, of course! There are many PII
So, there is a risk of data breach. Let’s lock it up. No, we need to share with other party to do research
OK, but how do you mitigate the risk of data breach? We can set the differential privacy policy, but you need to figure out the parameters
Can we set an alarm when someone accesses the sensitive data? Our counterpart is supposed to have some access to the data. How can we define what is sensitive?
I can’t imagine how I would react if the data team asked me to do threat modelling for their data clean room with differential privacy today.
However, I think differential privacy will definitely change how we protect data in the future, and we must learn its capability and limitations.